That's not my name
Back in primary school we were once asked to pick a name for ourselves other than our given name. I picked the name Ronald because it was a common name in many different languages (notably English, German and Dutch). With it being common meant the name Ronald would rarely be misspelled or mispronounced. A problem I have since encountered a number of times with my own name. So much so that I started collecting data on it. Below is a list of names people have called me (in person or over mail):
(pseudo_names <- tibble::tibble("Name"=c("Adman", "Adnam", "Adrian", "Adam", "Anand", "Ad", "Aad")))## # A tibble: 7 x 1
## Name
## <chr>
## 1 Adman
## 2 Adnam
## 3 Adrian
## 4 Adam
## 5 Anand
## 6 Ad
## 7 AadSpelling mistakes happen and pronouncing names can be difficult. Sometimes it can be surprising: I figured out people called me ‘Adrian’ because in some fonts, in particular handwritten text, the letters ‘r’ and ‘i’ next to each other resemble the letter ‘n’. And sometimes it can be annoying: short versions should be avoided at all cost1.
Adnan who?
The name Adnan in Arabic means “settler” but that is not the main reason for it’s popularity. Adnan (the historic figure) is considered to be the founder of the Adnanite branch of Arabs, he even has his own Wikipedia page. He was already popular pre-Islam but his popularity only increased after Islam because the Prophet Muhammad (pbuh) is one of his descendants. In current times, the name mostly occurs in the Middle East, Turkey and Pakistan.
You had me at A.
What other people mistakenly call you is influenced by many factors. Culture and language probably play a large role but I also think how similar different names are plays a role. And unlike culture and language we can quantify similarity. This will then hopefully show what names are more likely to occur. So how do we quantify how similar two names are? By measuring string similarity.
According to Wikipedia, “a string metric is a metric that measures distance (”inverse similarity“) between two text strings for approximate string matching or comparison and in fuzzy string searching”. Wikipedia lists 19 different string metrics that are applied in almost as many different areas. For my usecase, I’ll stick to Levenshtein distance which is one of the more basic ones2. I won’t go into the definition of each metric as that would make this a very boring blogpost, also the Wikipedia entries do a pretty good job already.
Instead let’s see what the Levenshtein distance applied to my “pseudonames” looks like. I’ll be using Mark van der Loo’s stringdist package to calculate string similarities.
library(stringdist)
pseudo_names <- mutate(pseudo_names,
LV=stringsim("Adnan", Name, method='lv'))
pseudo_names## # A tibble: 7 x 2
## Name LV
## <chr> <dbl>
## 1 Adman 0.8
## 2 Adnam 0.8
## 3 Adrian 0.667
## 4 Adam 0.6
## 5 Anand 0.6
## 6 Ad 0.4
## 7 Aad 0.4The values make sense, the names “Adam” and “Anand” are different but seem equally strange choices to me and that is reflected in the scores. A table is nice but a graph is of course better, thanks to Thomas Lin Pedersen’s ggraph.
library(ggraph)
library(tidygraph)
pseudo_names %>%
mutate(from="Adnan", to=Name) %>% # add connections
as_tbl_graph() %>% # convert to graph object
ggraph(layout='kk', weight=1/igraph::E(.)$LV) + # the weights will be converted to edge length
geom_edge_link(aes(start_cap = label_rect(node1.name),
end_cap = label_rect(node2.name))) + # *_cap needed to prevent edges to overlap labels
geom_node_label(aes(label=name)) +
theme_void()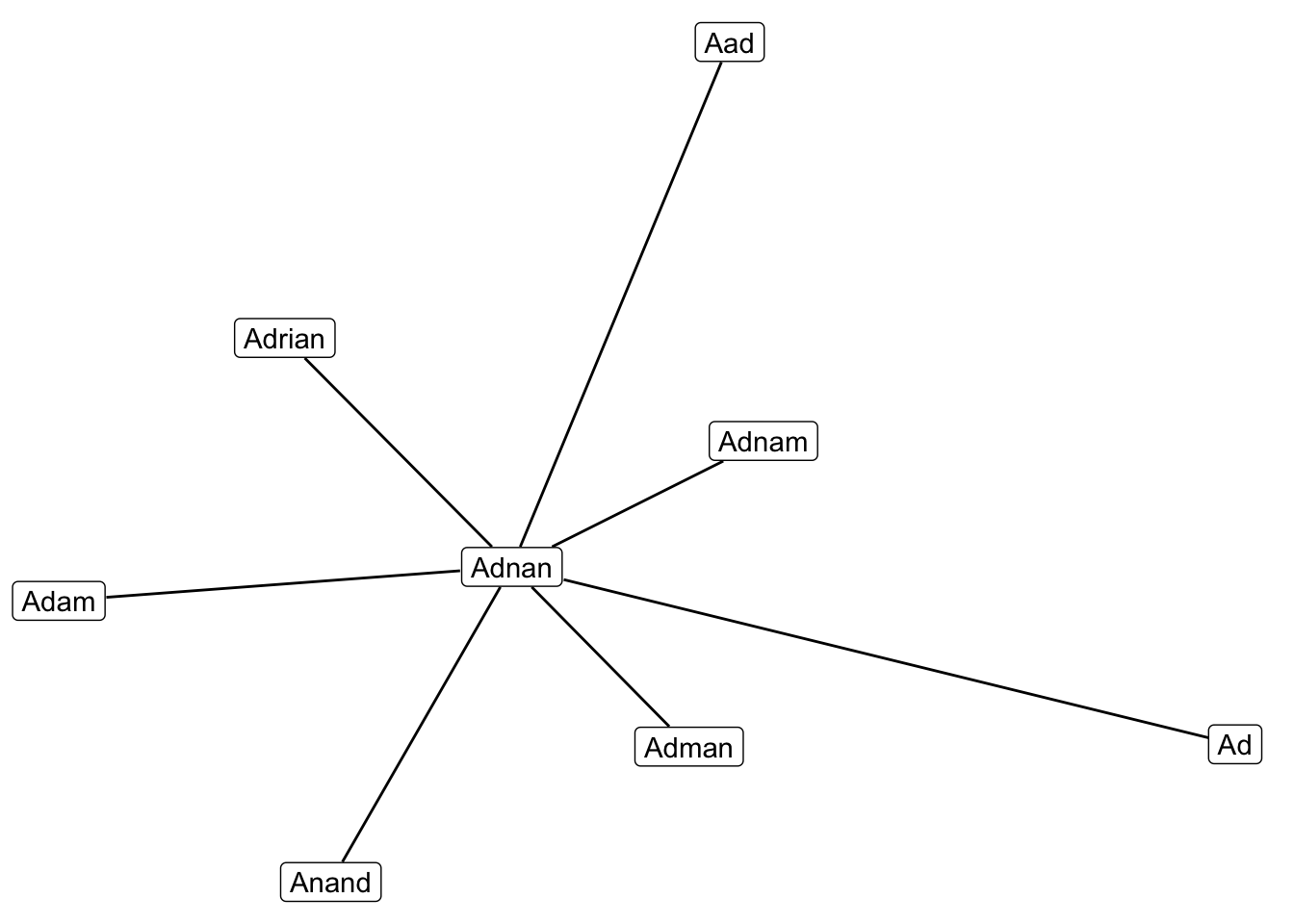
They call me Mister A!
The above pseudonames are the ones I know of but what about the ones I don’t know of. Let’s make things more interesting and include a corpus of names to see what other names are similar to my own.
Finding a corpus of names wasn’t easy, there weren’t that many that fitted my requirements. For example, the UK Office of National Statistics publish a list of the most common baby names every year. However this list doesn’t mention all names in circulation and only goes back a few years. Asked if they keep track of all names they replied “uuhhmm…no”. On the other hand there is the names database from the Meertens Institute, which deserves a special mention. They not only show usage of a name over time but also provide a great explanation/meaning. Unfortunately it is very much focused on Dutch names but if you are one of those lucky people then do check it out.
I finally settled for the babynames package maintained by Hadley Wickham. Although it’s sourced from the US Social Security Administration I expect it to be a reasonable representation of Western names.
library(babynames)
all_names <- babynames %>%
select(name) %>%
distinct()
paste("Number of unique names: ", nrow(all_names))## [1] "Number of unique names: 97310"Now that we have all these names, we can compare them to my own. I’ll use the same code as above to generate another graph.
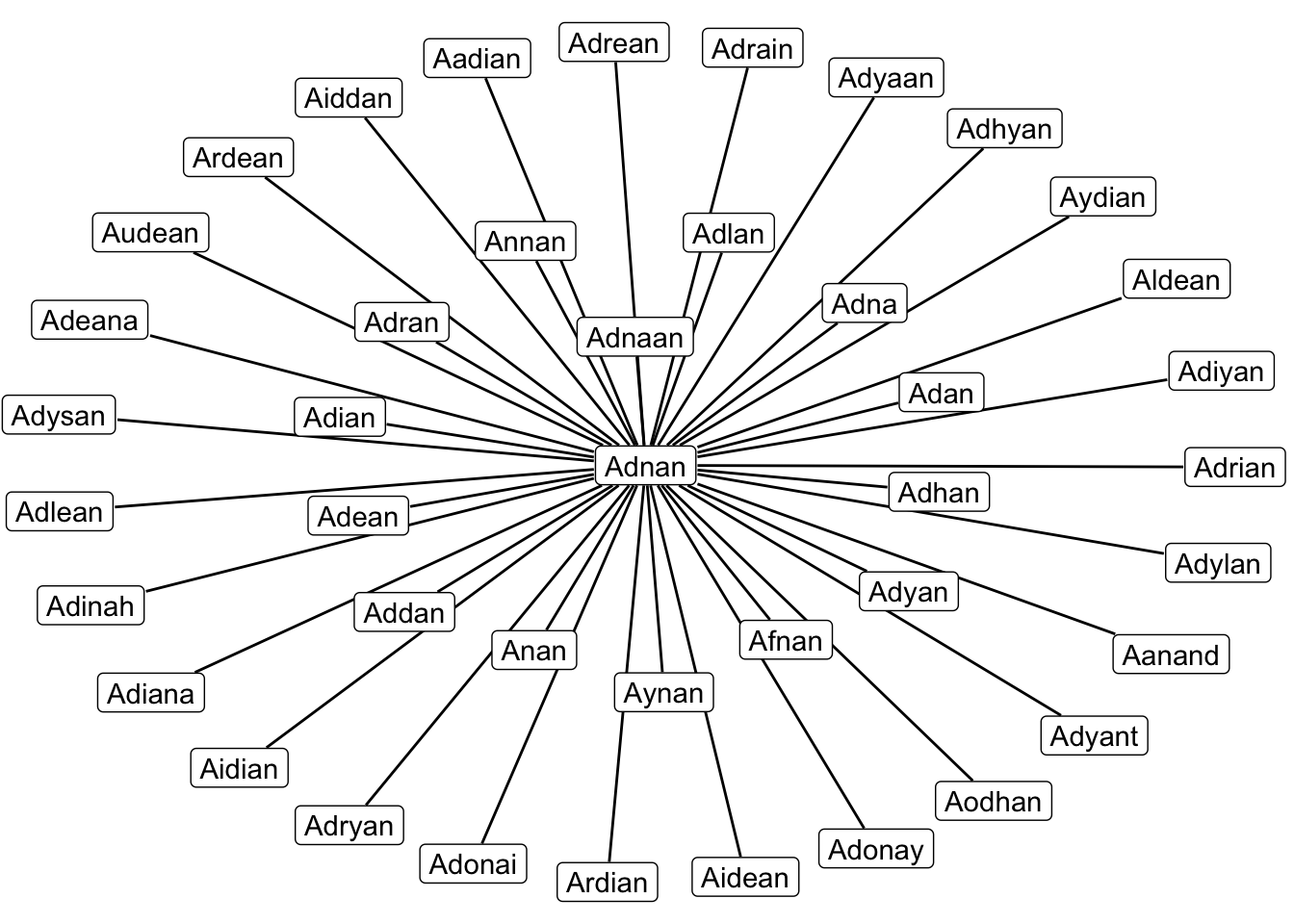
I have filtered out names with a similarity value below 0.6 to make the graph easier on the eyes. The result is definitely surprising as these are names I’ve never heard of, except Adrian of course. The name most similar to mine is Adnaan but I’ve never come across my name being spelled with two a’s. The way the graph looks it feels like some sort of underground evil organisation with an inner circle of bosses and outer circle of minions but maybe that’s just me3.
That’s not my name
There are of course a number of caveats with the above analysis. First, I compared against existing names (in the US) and not possible misspellings. Finding such a dataset would be considerable harder. Second, I seriously doubt anyone will ever call me Ardian or Aidean. As such string similarity may not be an accurate metric for finding names you might be called.
Nevertheless I very much enjoyed exploring the different names in the babynames package from a similarity perspective. If you also want to have a go, I’ve created a shiny app (code on GitLab | GitHub) in which you can check out your own “name similarity”-graph.
And I’m not done with babynames just yet, check out next week’s blogpost where I take name similarity to another dimension. Or as I like to call it: The Name Similarity Vortex.
I wonder if there’s an alternate dimension where people elongate names rather than shorten them.↩
It would perhaps make more sense to use one of the phonetic string metrics but I’ve chosen to keep things simple. Also even phonetically a name can be different across languages.↩
I thought about calling it The A-Team but I hear that name is already taken.↩